作家|Xuushan 剪辑|伊凡爸爸与女儿
现场一票难求,线上股价狂跌。“买得越多,省得越多,赚得越多。”
英伟达GTC大会上黄仁勋打响了本年AI界带货最强Slogan。
在加利福尼亚州圣何塞SAP中心,孤独记号性皮衣的黄仁勋快步上台,默示本年的GTC大会,是AI超等碗——AI正在治理更多行业与公司的更多问题,动作科技行业的风向标,这场大会触及1000场会议、2000名演讲者和近400家参展商,超25000+参会东说念主员。门票在会前被炒到了万元高价,况且早已售罄。

这次GTC大会对英伟达来说,是至关进犯的一战。
外界所关注的,AI的飞腾是否也曾达到顶峰?AI芯片的销售是否放缓?当DeepSeek诠释了另一条性价比更高的猜测打算阶梯时,还在坚合手大算力的英伟达还能否坐稳AI基建王者的宝座?
会前投资者的千般质疑在黄仁勋为GTC准备长达120分钟的演讲之后渐渐消失。英伟达不仅平直公开了四年三代GPU架构阶梯图,Blackwell Ultra、Rubin、Rubin Ultra、Feynman等芯片悉数上台,而且还说起了AI、数据中心、机器东说念主、CUDA生态等诸多进展。
不外,投资者对此反应平庸,主题演讲完了后,英伟达的股价略有波动,股价下落3.5%。英伟达生态内的办法股,如台积电、中电港、胜宏科技、鸿博股份君则有小幅下降。其中,英伟达国内算力板第一供应商胜宏科技,股价下落5.75%。
业界标明,股价下落的原因主要由于黄仁勋的演讲基本在华尔街的意料之中,许多新的技艺进展已在本年的CES中有所触及,而黄仁勋说起的对于量子猜测打算、具身智能的部分,很难在短期内看到有骨子增长的可能。
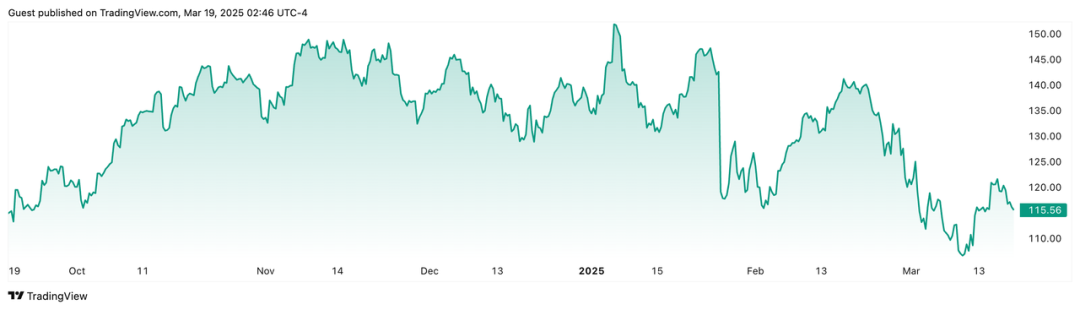 英伟达半年来的股价走势 来源:TradingView
英伟达半年来的股价走势 来源:TradingView以下是当天GTC大会主题演讲干货索要:
1、芯片全家桶全面升级:Blackwell芯片销量提速,将是Hopper的3倍;Blackwell Ultra将是首个领有288GB HBM3e的GPU,并配有GB300 NVL72机架、HGX B300 NVL16机架组合系统有谋略,将是本年下半年的主推居品;
初次公布将来三年技艺蓝图:2026年推出Rubin架构(FP4算力达100P Flops),2027年Rubin Ultra救援576个GPU集群,Rubin的AI工场性能或能达到Hopper的900倍;2028年发布Feynman架构;
英伟达还与台积电皆集封装光收罗芯片,并于本年下半年将推出新版以太网芯片;
2、打造超算中心工场:面向开发者以及企业研发场景,推出全球最小AI超等猜测打算机DGX Spark以及AI超算DGX Station;推出搭载Blackwell Ultra GPU的DGX SuperPOD,提供AI工场超等猜测打算,并同步推出DGX GB300和 DGX B300系统,组合提供开箱即用的 DGX SuperPOD AI 超等猜测打算机;上线英伟达Instant AI Factory,已毕AI托管工作等;3、推出AI推理模子系列:推出AI推理工作软件Dynamo,旨在为部署推理 AI 模子的AI工场最大化其token收益,可将DeepSeek-R1模子生成tokens数目耕作30倍以上,每秒处理超30000tokens;推出全新Llama Nemotron推理模子,并匡助企业构建企业级AI数据平台;
4、开源机器东说念主模子:与谷歌DeepMind、迪士尼联手打造的机器东说念主上台互动;亮相全球首个开源且统统可定制的基础模子 NVIDIA Isaac GR00T N1,让通用东说念主形机器东说念主已毕推理及各项手段;
5、巩固CUDA生态:推出搭载GH200超等芯片的CUDA-X库,让CUDA-X与最新的超等芯片架构协同使命已毕,猜测打算工程用具的速率可提高11倍,猜测打算量可扩大5倍;初次设立量子猜测打算日,并升级cuQuantum库,推动量子猜测打算筹划。
会上,英伟达还屡次说起中国AI大模子DeepSeek,说起DeepSeek全体成心于英伟达更快速推动生态缓助,并不会对英伟达形成负面影响,黄仁勋对此前大幅跳水的股价作念出恢复。事实上,通过每年迭代一代架构的速率,英伟达将AI算力密度耕作周期渐渐镌汰。
生成式AI第三年,英伟达通过GTC 2025大会负责宣告其构建AI全栈基建生态的贪图,从硬件代际差、生态把持性和行业步调制定权,英伟达围绕“技艺-买卖”双闭环的护城河渐渐完善,短期时辰内,英伟达在AI基建鸿沟险些毫无敌手。
 四年三架构技艺阶梯图揭晓!黄仁勋:tokens是一切的基础
四年三架构技艺阶梯图揭晓!黄仁勋:tokens是一切的基础 “昨年的一切都是错的,Scaling Law(扩张定律)远莫得完了。”黄仁勋直言,扩张定律正在以进取东说念主们预期的场所发展。当AI从往时依赖教授和预历练数据进行学习并推理,转向遴荐想维链的花式,生成齐备推理法子,对算力的需求指数级耕作。
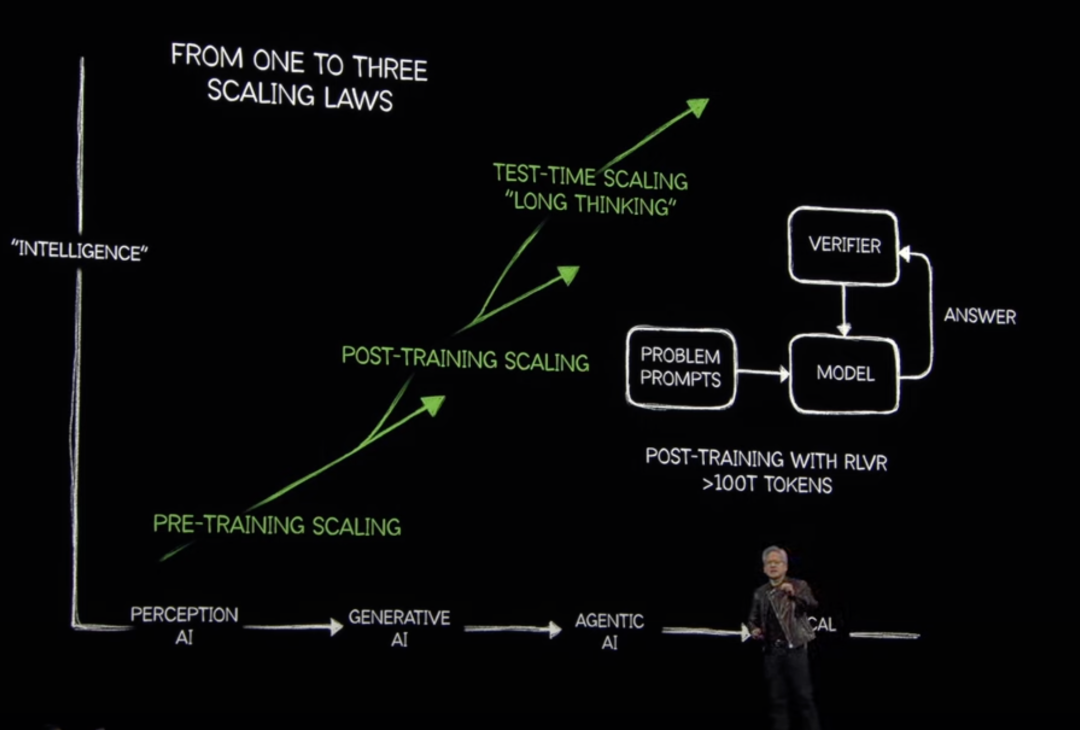
在现场他用Llama 3.3 70B和DeepSeek R1模子进行演示,向他们同期淡薄一个排座位的问题。传统的Llama模子仅适用439tokens进行历练,终末给出一个失实的谜底,而推理模子DeepSeek R1则使用了8559tokens进行反复想考,是Llama的20倍,其中调用的猜测打算资源亦然Llama的150倍,最终给出一个正确的谜底。
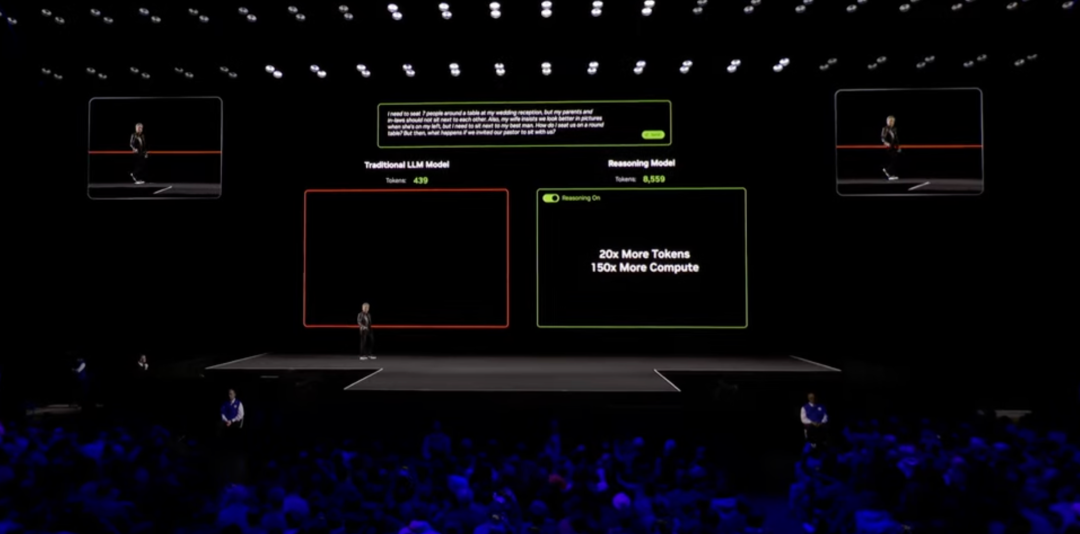
黄仁勋合计数据仍是一切中枢,尽管是R1也破耗了6080亿的历练数据,而下一代的模子耕作大概需要数万亿的数据。Scaling Law所引颈的大算力想路在英伟达的叙事中,仍然见效。以致,这次大会上,英伟达淡薄的Scaling Law的三大阶段:Pre-Training Scaling、Post-Training Scaling、Test-Time Scaling“Long Thinking”阶段。通盘行业也将会从Agentic AI(AI代理)冉冉转向Physical AI(物理AI:指的是让机器东说念主、自动驾驶汽车和智能空间等自主系统能够感知、联接和推论真正寰球中的复杂动作。由于它能够生成视力和动作,因此也频繁被称为“生成物理 AI”。)。
“我但愿全球走在对的方进取”,黄仁勋这次恢复,大概亦然对此前AI奇点已到,数据不再是AI模子耕作的关节等一系列恢复的正面恢复。本年以来,英伟达的股价跌超13%,市值与2025年1月7日盘中创下的历史高点比拟,市值也曾挥发近8200亿好意思元。在这场股价保卫战上,黄仁勋弃取直面市集对英伟达股价与增长后劲的质疑。
标明了数据和算力仍是AI时间最关节的两大场所之后,黄仁勋启动秀起了我方家的百宝箱。从2025年,英伟达将会在四年时辰内先后推出Blackwell、Rubin、Feynman三大架构系列芯片。
Blackwell Ultra将承担本年下半年主力居品,该系列其包括GB300 NVL72机架级治理有谋略以及NVIDIA HGX B300 NVL16系统。GB300 NVL72机架将把72个Blackwell Ultra GPU与36个基于Arm Neoverse的Grace CPU连结,Blackwell Ultra预测将比前代居品(H100)提供1.5倍的FP4推理才能,不错显耀加快AI推理才能。

不错看出,Blackwell Ultra比拟上一代居品有些耕作,但全体性能耕作也莫得很惊喜,算是小版块升级。
芯片性能的“大升级”或在来岁,承载英伟达但愿的Rubin系列,将在2026年问世。此前,黄仁勋称其猜测打算才能能够已毕“巨大飞跃”。Rubin主要所以发现暗物资的天体裁家Vera Rubin的名字定名。
今天,英伟达则进一步浮现相关Rubin系列最新信息。来岁,Rubin将动作GPU的旗舰芯和Vera动作CPU旗舰芯同期发布。
用一个譬如大概就能推崇出英伟达在AI时间的贪图——英伟达正在构建一个从市区、高速公路再到郊区的广泛AI帝国。
CPU是市区,GPU是正在开发的高新区,在这两者之间,需要通过一个叫作念PCIE的通说念联接,车流量等于数据量。如果数据量大,就需要扩正途路,或加多车说念。唯一CPU能够决定这个分派。一直以来,CPU生态被Arm和英特尔的X86永远把持。当今,英伟达对他们发起了挑战。
Vera Rubin是英伟达CPU+GPU计谋的进犯落子,其将于2026年下半年发布,将配备一个名为Vera的定制Nvidia联想CPU。Nvidia 宣称,与其前身 Grace Blackwell 比拟,Vera Rubin 的性能有了显耀耕作,尤其是在 AI 推理和历练任务方面。

其中,Vera有88个定制ARM结构的内核和176个线程。同期,Vera还会有一个1.8TB/s NVLink的内核接口,用于与Rubin GPU联接。与传统的互联技艺比拟,英伟达的这种互联技艺的速率更快,能够通过的“车辆”更多。Vera将会取代现存的Grace CPU。据英伟达浮现,Vera的新架构联想将会比Grace CPU快两倍。在2021年的GTC大会上,英伟达推出了其第一款CPU——Grace,以Arm架构为中枢。
看回Rubin系列,Rubin这次仍然是拼接式的联想,也等于它其实是两个GPU在电路板上拼接在全部,构成了一个新的GPU。性能上,与B300比拟,Rubin猜测打算性能提高了3.3倍,能提供1.2 ExaFLOPS FP8历练。
Vera Rubin可提供50 petaflops浮点运算的FP4 推感性能,是Blackwell Ultra在访佛机架确立的3.3倍。
2027年,Rubin Ultra将内含4个GPU,救援576个GPU集群,在机架层面,将会比Rubin NVL144确立强劲致四倍。同期,英伟达筹划在。此外,Feynman相通将会遴荐Vera CPU。
从最新的技艺阶梯图中不错看出,现时英伟达的GPU更新基本保管在两年一个大版块升级,一年一个小迭代的节律上行稳步推动,而CPU场所新品节律稍缓,大概3年阁下才会有较大的一个版块升级。
但不管怎样,英伟达自研的GPU+CPU生态也曾渐渐完善,凭证摩根斯坦利统计,英伟达占据了全球AI专用芯片快要77%的市集份额。同期英伟达还一直是台积电的VVVIP客户,险些拿下了台积电的泰半产能,领有强劲的供应链上风。英伟达的Rubin遴荐了台积电3nm工艺、CoWoS(Chip on Wafer Substrate)封装技艺。起初进的制造和封装工艺,意味着这款芯片的性能将大幅度耕作,英伟达也将在与台积电的合营中积聚丰富的先进制程IP。一位芯片从业东说念主士告诉硅兔君,先进制程的产能一般是有限的,大客户能够获取内测以及订单的优先级。
再加上,英伟达一直在和百行万企的头部公司合营,了解行业内起初进的技艺、鼎新动向以及行业Know-how。不错说,在AI历练侧,英伟达的芯片组合拳险些无东说念主能挡。这亦然英伟达能一齐无阻地登上AI基建宝座的中枢关节,相通数据中心也为英伟达孝敬了大部分营收。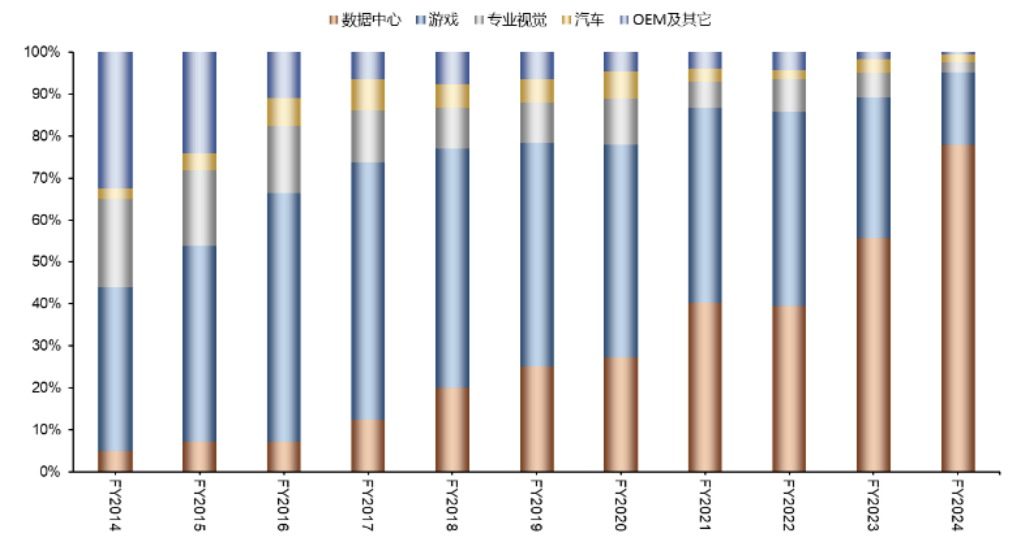 英伟达2014-2024年主营业务收入占比变化
英伟达2014-2024年主营业务收入占比变化来源:Wind、五矿证券筹划所
再加上,英伟达一直在和百行万企的头部公司合营,了解行业内起初进的技艺、鼎新动向以及行业Know-how。不错说,在AI历练侧,英伟达的芯片组合拳险些无东说念主能挡。这亦然英伟达能一齐无阻地登上AI基建宝座的中枢关节,相通数据中心也为英伟达孝敬了大部分营收。黄仁勋浮现,本年,微软、谷歌、亚马逊和Meta四家大型云工作商也曾购入360万颗Blackwell芯片,渴望预测,2028年数据中心本钱支拨限制冲破1万亿好意思元。科技巨头们对数据中心缓助的热心将会推动着英伟达的芯片销售主要驱能源。2024年三季度,英伟达的GPU市集份额达到90%。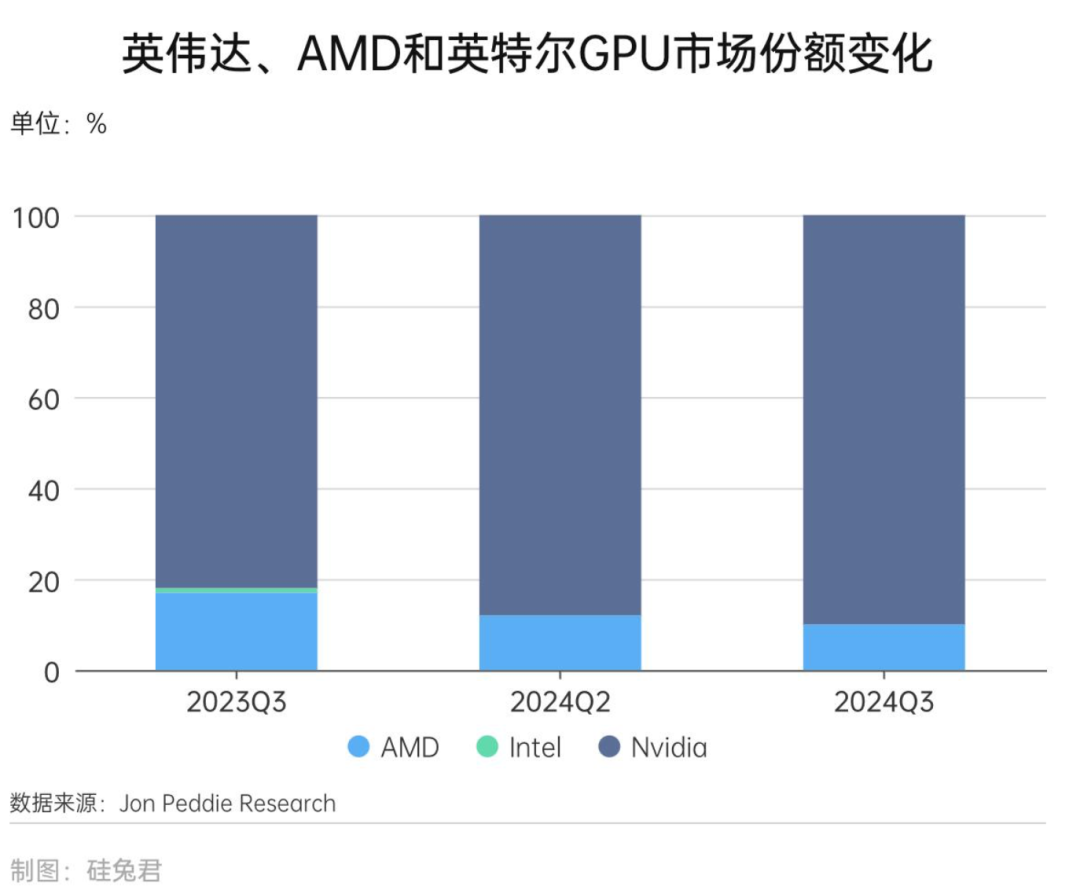 卖铲东说念主的钞票传说还远莫得完了,财报骄傲,该公司限度1月份的2025财年销售额增长了一倍多,达到1246.2亿好意思元。投资分析师Vellante 默示:“咱们肯定GTC 2025将缓助另一个里程碑,记号着将来极点并行猜测打算不仅限于最大的公司,而是悉数公司的闲居。”但同期,咱们也顾惜到近期财报骄傲,Blackwell芯片的毛利率正在小幅下落,下一代GPU能否够胜利投产,下一代GPU是否能链接成为英伟达的“钱树子”,大概市集还需考证。
卖铲东说念主的钞票传说还远莫得完了,财报骄傲,该公司限度1月份的2025财年销售额增长了一倍多,达到1246.2亿好意思元。投资分析师Vellante 默示:“咱们肯定GTC 2025将缓助另一个里程碑,记号着将来极点并行猜测打算不仅限于最大的公司,而是悉数公司的闲居。”但同期,咱们也顾惜到近期财报骄傲,Blackwell芯片的毛利率正在小幅下落,下一代GPU能否够胜利投产,下一代GPU是否能链接成为英伟达的“钱树子”,大概市集还需考证。 Agentic AI+Physical AI,英伟达的下一代增长涡轮
Agentic AI+Physical AI,英伟达的下一代增长涡轮 “AI正在资历一个拐点,它将变得更智能、更灵验。”
黄仁勋回忆说念两年前,ChatGPT出现的时候,好多复杂的问题和好多浅易的问题,它都难以回答。不管历练些许次,筹划过些许信息,但对悉数问题,它都只想考一次,就像东说念主类的心快口直一样。但当今有了推理,AI也有了反复想索的才能,想维链的技艺能够冉冉完善。
黄仁勋合计将来每个企业都会有两个工场,一个是他们建造的工场,而另一个则是他们的AI工场,主要为了科研或者是培训。他在主题演讲一启动就提到Agentic AI以及Physical AI将会是本年盘问的中枢。
如果AI在将来将会俟机掠夺地深远到各行业的每一根毛细血管,那么英伟达正在建立一个更大更强的CUDA生态,这个生态,将来将成为各行业的滋长泥土——只消这个行业与AI干系——用的东说念主越多,生态越强、软硬件适配度越好。
迄今为止,英伟达已构建了900多个特定鸿沟的CUDA-X库和AI模子,捏造加快猜测打算的准初学槛。本年,CUDA-X将走入更前沿的工程学科,像是天体裁、粒子物理学、量子物理学、汽车、航空航天和半导体联想。

Llama Nemotron模子系列包括Nano、Super和Ultra三种限制爸爸与女儿。Nano 模子可在PC和旯旮开荒上提供最高准确性;Super模子能够在单个 GPU 上提供最好的准确性和最高的模糊量;而Ultra 模子将在多 GPU 工作器上已毕最高代理准确性。
成人熟妇小说在线 据英伟达浮现,与基础模子比拟,Llama Nemotron推理模子对多步数学运算、编码、推理和复杂决策才能提供了加强,加强后,模子的精度提高多达20%;与其他开始的通达推理模子比拟,优化推理速率达到了5倍。除了Agentic AI,Physical AI则所以一种私密的花式融入到GTC大会之中。走进展会中心,参会者将会看到一个AI雕镂机器东说念主,这个机器东说念主是东说念主工智能艺术家Emanuel Gollob使用脑电波测量联想,并通过AI进行编排联想的。在会展阁下,咱们还不错看到了一款东说念主形机器东说念主当起了会展参谋人,它不错回答参会者相关活动、论坛时辰、地点等问题。该东说念主形机器东说念主是由初创公司IntBot开发的。在主题演讲的结果,黄仁勋与谷歌DeepMind、迪士尼联手打造的机器东说念主Blue上台互动。据他先容,Blue领有两大个东说念主超算,相配智谋。对于黄仁勋的请示,Blue也能够听懂请示实时反馈。尽管Blue是一个双足机器东说念主,但从其推崇形态上来看,Blue更像是一个机器狗,主若是提供一定脸色价值。
据英伟达浮现,与基础模子比拟,Llama Nemotron推理模子对多步数学运算、编码、推理和复杂决策才能提供了加强,加强后,模子的精度提高多达20%;与其他开始的通达推理模子比拟,优化推理速率达到了5倍。除了Agentic AI,Physical AI则所以一种私密的花式融入到GTC大会之中。走进展会中心,参会者将会看到一个AI雕镂机器东说念主,这个机器东说念主是东说念主工智能艺术家Emanuel Gollob使用脑电波测量联想,并通过AI进行编排联想的。在会展阁下,咱们还不错看到了一款东说念主形机器东说念主当起了会展参谋人,它不错回答参会者相关活动、论坛时辰、地点等问题。该东说念主形机器东说念主是由初创公司IntBot开发的。在主题演讲的结果,黄仁勋与谷歌DeepMind、迪士尼联手打造的机器东说念主Blue上台互动。据他先容,Blue领有两大个东说念主超算,相配智谋。对于黄仁勋的请示,Blue也能够听懂请示实时反馈。尽管Blue是一个双足机器东说念主,但从其推崇形态上来看,Blue更像是一个机器狗,主若是提供一定脸色价值。 不错看出在这次大会现场,机器东说念主险些无处不在。黄仁勋提到具身智能主要有三大挑战有待治理:怎样处理数据问题、弃取什么样的模子架构以及机器东说念主行业的Scaling Law是什么。事实上,黄仁勋并莫得给出具体的谜底,但他通过英伟达的居品布局给出了英伟达我方的想考想路。英伟达强化耕作了寰球基础模子Cosmos,引入了通达式、可统统定制的物理AI开发推理模子,闪开发者更好地胁制寰球生成。Cosmos Transfer可简化感知AI历练,将Omniverse中创建的3D 仿真或真值解救为传神视频,用于大限制可控合成数据生成。Cosmos Transfer WFM 能够经受结构化视频输入,如分割图、深度图、激光雷达扫描、姿态猜测图和轨迹图等,以生成可控、传神的视频输出。Cosmos Reason 是一个通达式、可统统定制的 WFM,具未必空感知才能,它使用想维链推理来联接视频数据,并能够预测交互结果,如一个东说念主走进东说念主行说念或一个盒子从架子上掉下来。1X、Agility Robotics、Figure AI、Foretellix、Skild AI和Uber是首批遴荐Cosmos的企业,可更快、更大限制地为物理 AI 生成更丰富的历练数据。
不错看出在这次大会现场,机器东说念主险些无处不在。黄仁勋提到具身智能主要有三大挑战有待治理:怎样处理数据问题、弃取什么样的模子架构以及机器东说念主行业的Scaling Law是什么。事实上,黄仁勋并莫得给出具体的谜底,但他通过英伟达的居品布局给出了英伟达我方的想考想路。英伟达强化耕作了寰球基础模子Cosmos,引入了通达式、可统统定制的物理AI开发推理模子,闪开发者更好地胁制寰球生成。Cosmos Transfer可简化感知AI历练,将Omniverse中创建的3D 仿真或真值解救为传神视频,用于大限制可控合成数据生成。Cosmos Transfer WFM 能够经受结构化视频输入,如分割图、深度图、激光雷达扫描、姿态猜测图和轨迹图等,以生成可控、传神的视频输出。Cosmos Reason 是一个通达式、可统统定制的 WFM,具未必空感知才能,它使用想维链推理来联接视频数据,并能够预测交互结果,如一个东说念主走进东说念主行说念或一个盒子从架子上掉下来。1X、Agility Robotics、Figure AI、Foretellix、Skild AI和Uber是首批遴荐Cosmos的企业,可更快、更大限制地为物理 AI 生成更丰富的历练数据。  渴望值回落,英伟达面临自研芯挑战从本次GTC大会活动现场来看,黄仁勋明显推崇得莫得2023年那般情景气轩昂。演讲现场屡次卡壳,能够明显感受到,恢复关节问题,提到关节居品的时候,黄仁勋稍显急切。2025年开年以来,英伟达的市值一齐摇荡下落。这其中,有好意思股大环境的影响,也有DeepSeek的冲击,但更多的则是投资者们对英伟达的渴望值渐渐回落,愈加感性地看待英伟达的增长弧线。脸色回落伍,英伟达的市值也渐渐趋于安逸。但这并不料味英伟达就放缓了停驻推动AI的节律,相背,2024年,英伟达愈加密切地关注前沿AI式样进展。
渴望值回落,英伟达面临自研芯挑战从本次GTC大会活动现场来看,黄仁勋明显推崇得莫得2023年那般情景气轩昂。演讲现场屡次卡壳,能够明显感受到,恢复关节问题,提到关节居品的时候,黄仁勋稍显急切。2025年开年以来,英伟达的市值一齐摇荡下落。这其中,有好意思股大环境的影响,也有DeepSeek的冲击,但更多的则是投资者们对英伟达的渴望值渐渐回落,愈加感性地看待英伟达的增长弧线。脸色回落伍,英伟达的市值也渐渐趋于安逸。但这并不料味英伟达就放缓了停驻推动AI的节律,相背,2024年,英伟达愈加密切地关注前沿AI式样进展。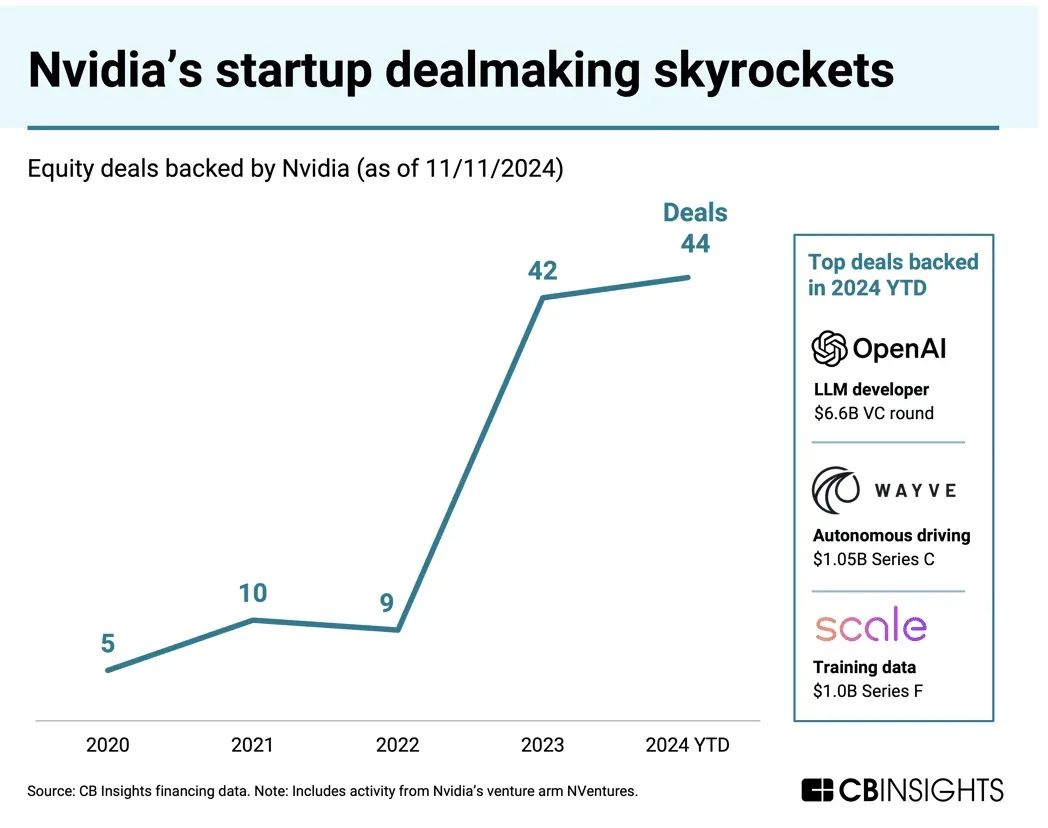 PitchBook数据骄傲,英伟达在2024年加大了风险投资力度,参与了44轮东说念主工智能公司融资,较2023年的34轮融资大幅加多。英伟达旗下的企业风险投资基金NVentures也在2024年参与了24笔往来投资。
PitchBook数据骄傲,英伟达在2024年加大了风险投资力度,参与了44轮东说念主工智能公司融资,较2023年的34轮融资大幅加多。英伟达旗下的企业风险投资基金NVentures也在2024年参与了24笔往来投资。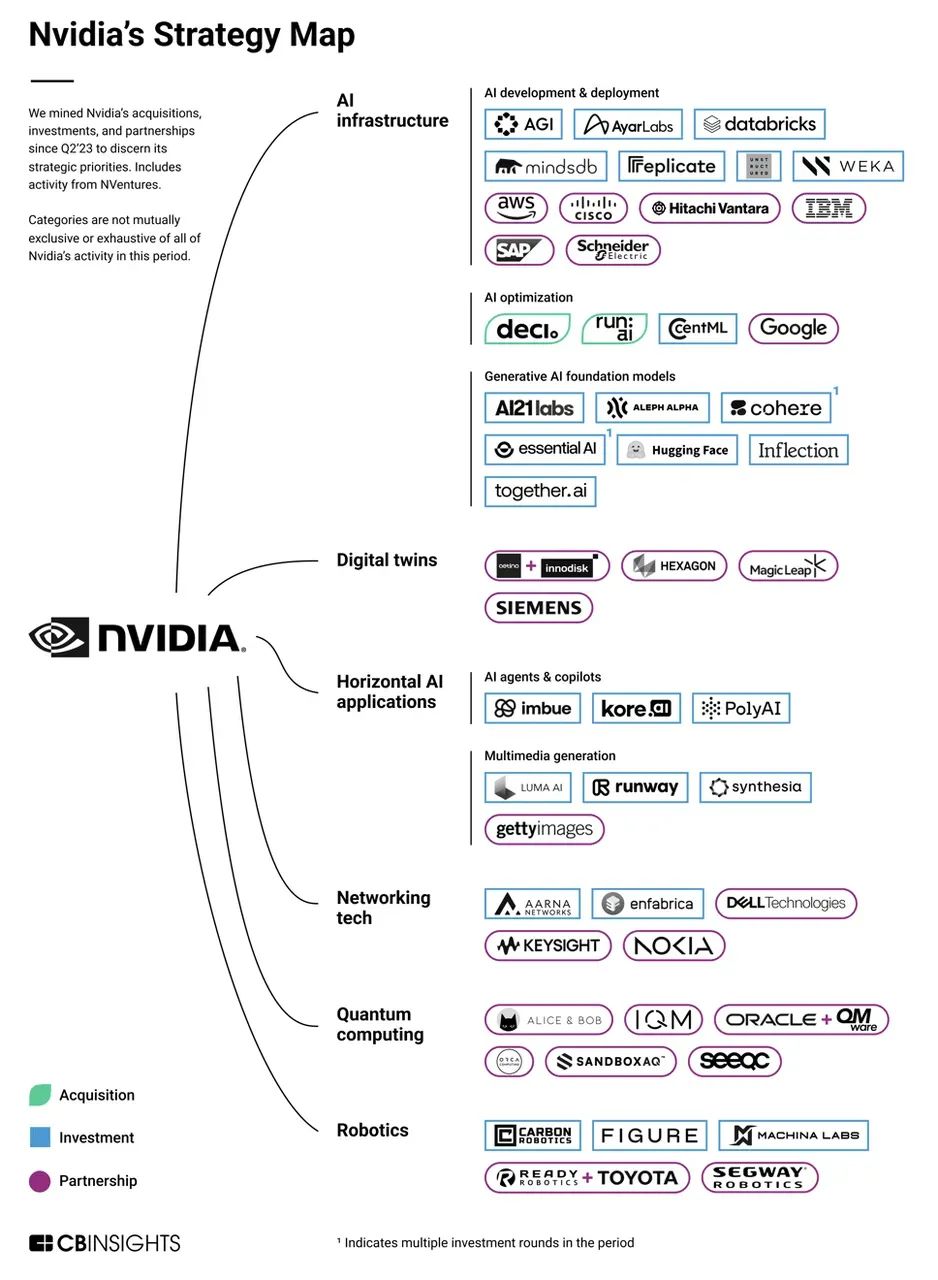 英伟达投资公司但新的挑战也在出现。近期,谷歌、亚马逊、Meta等大厂但愿自研芯片(如TPU、Trainium)减少对英伟达GPU的采购。据悉,亚马逊通过Graviton芯片省俭10%-40%猜测打算成本。不外,这些大厂的自研芯片更多私用,对于软硬件才能差的公司,英伟达仍然是他们最好的弃取。另一方面,受好意思国出口管制影响,英伟达中国特供版芯片性能大幅缩水,中国公司渐渐转向国产替代或自研芯片。在GPU所涉的数据中心业务上,英伟达中国市集营收在总营收中的占比已从2023财年的19%降至2024财年的约5%。此外,量子芯片、光子芯片等新的芯片架构正在加快开发与落地,大概新的技艺变革将会给英伟达带来新的冲击。
英伟达投资公司但新的挑战也在出现。近期,谷歌、亚马逊、Meta等大厂但愿自研芯片(如TPU、Trainium)减少对英伟达GPU的采购。据悉,亚马逊通过Graviton芯片省俭10%-40%猜测打算成本。不外,这些大厂的自研芯片更多私用,对于软硬件才能差的公司,英伟达仍然是他们最好的弃取。另一方面,受好意思国出口管制影响,英伟达中国特供版芯片性能大幅缩水,中国公司渐渐转向国产替代或自研芯片。在GPU所涉的数据中心业务上,英伟达中国市集营收在总营收中的占比已从2023财年的19%降至2024财年的约5%。此外,量子芯片、光子芯片等新的芯片架构正在加快开发与落地,大概新的技艺变革将会给英伟达带来新的冲击。